Neuronpedia – Scoping out LLM-brains.
That is quite literally what you can do with a demo from Neuronpedia, a platform for AI interpretability. Whats that again? Mechanistic Interpretability is the field of research focused on understanding the inner workings of AI.

Want to put the brain of a LLM under a microscope?
That is quite literally what you can do with a demo from Neuronpedia, a platform for AI interpretability. Whats that again? Mechanistic Interpretability is the field of research focused on understanding the inner workings of AI.
One way to do that is using sparse autoencoders (SAEs) on each layer of a LLM to find common features. Creating this level of abstraction makes it more understandable to humans what parts of the LLM activate when prompted.
So how do we make use of those SAEs now? We can adjust identified features to steer the model's output. Altough this is quite unreliable yet, in the future it could come in handy to reduce biases or block out harmful answers the LLM might be inclined to give.
You can try out this steering functionality on Neuronpedia itself. Turn Gemma-2-9B into a pirate for example:
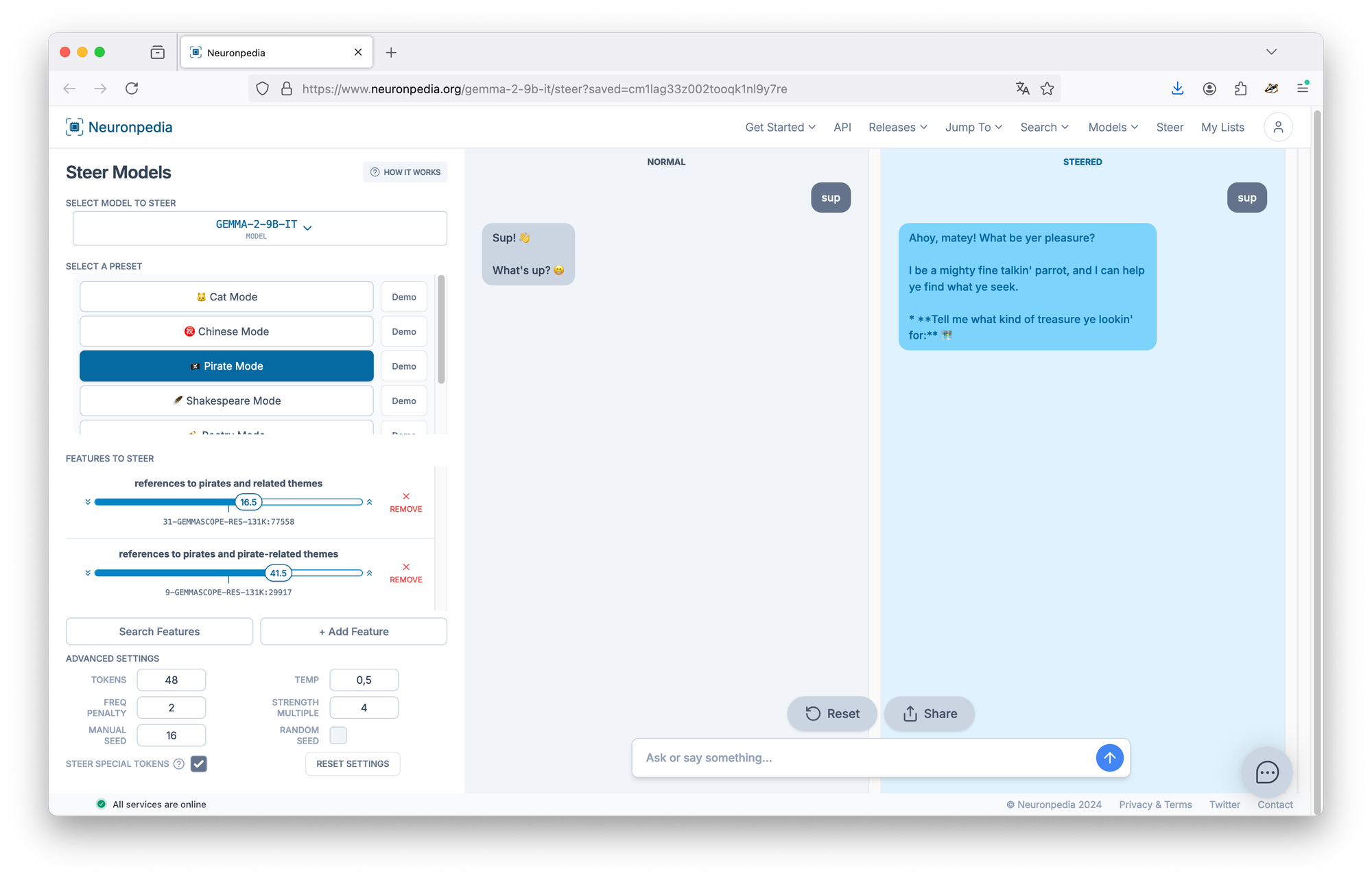
This is not simply prompt engineering. The input to the model is not changed at all. What is, is how the input gets processed and an output is created. We literally rewired the model! This illustrates the main advantage of safety. A steered model is much more difficult to jailbreak through prompting than one that is instructed not to explain how you could build a bomb for example.
“A limitation is the steering influencing a model by adjusting its parameters is just not working that well, and so when you steer to reduce violence in a model, it ends up completely lobotomizing its knowledge in martial arts. There’s a lot of refinement to be done in steering,” says Lin. The knowledge of “bomb making,” for example, isn’t just a simple on-and-off switch in an AI model. It most likely is woven into multiple parts of the model, and turning it off would probably involve hampering the AI’s knowledge of chemistry. Any tinkering may have benefits but also significant trade-offs.
Johnny Lin (Founder of Neuronpedia)
in MIT Technology Review
Try and learn through the demo here:
